Bob Elliott
VP Storage Solutions
The DS8000 is architected very differently from other enterprise-class arrays. First, how is it different? And second, what does that difference mean to those who deploy it?
The basic answer for how the architecture is different: Power. The DS8000 line uses IBM Power servers to run the system.
The DS8000 is a three-layered “share everything” architecture:
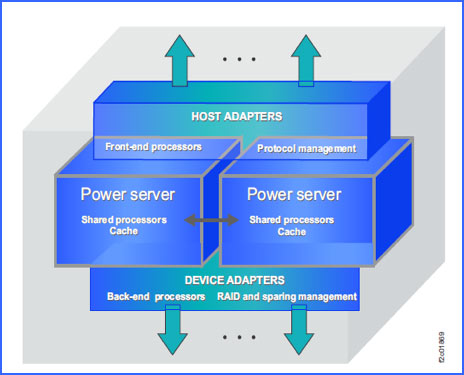
So, what advantages does Power offer in a disk array?
- Integrated cache and processors – unlike the “x86” based systems, there is no need for the I/O stream to stray outside of the processor base. L1, L2 and L3 caches all communicate directly for far lower latency and reduced risk. The Power8 SMP complex in the DS8880 is a massive data pump.
- Autonomic processing for increased reliability – the millions of variables that need to be managed when tracking and correcting errors results in microcode complexity. IBM Power processors inherited the firmware from the mainframe that handles error management. Eliminating hundreds of thousands of lines of code from microcode makes the microcode much simpler, and simple means reliable. Error management in the firmware is also much faster. PowerPC processors, used for host and disk array adapters, means additive power to the SMP’s. The host and array PowerPC processors are Application Specific Integrated Circuits (ASICS). This means that they are specifically designed for their mission.
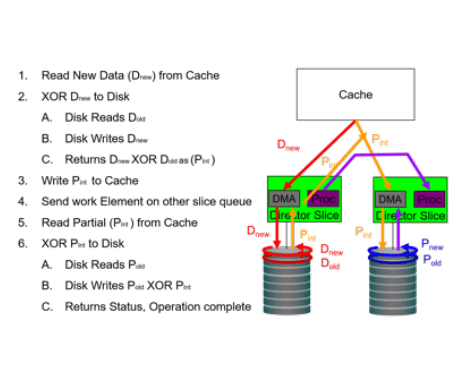
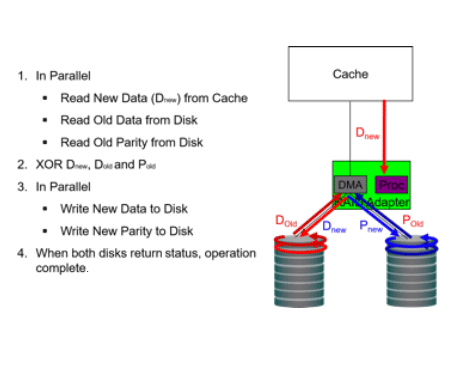
- Massive parallelism of I/O between the cache and disk arrays, which is enabled by the array ASICS. Unlike other arrays, the DS8000 allows for each disk in an array to directly process I/O’s in parallel with all the other disks in every array. Also, RAID5/6 parity processing is handled as only three parallel operations, rather than the six serial processes that typically handle RAID5/6 processing. The result is practical RAID5/6 deployments in high- performance applications. Over 90% of all DS8000’s are implemented with RAID5/6.
Normal RAID5/6 Processing
- Dramatic improvements in cache processing – the DS8000 utilizes a patented process for cache management called Adaptive Replacement Caching (ARC). Before ARC, the Least Recently Used (LRC) algorithm cleared cache of the oldest data to make room for new writes. But what if the oldest data was the data that benefitted from cache residency the most? ARC makes that determination. It clears the cache of the least-effective data. The result: DS8000 cache behaves as though it was twice as large as it actually is. Along with ARC is more effective cache segmentation. DS8000 uses a 4k segment size. HDS VSP utilizes a 16k segment size, and EMC VMAX utilizes a 64k size. So, for any data write that is larger than 4k there is cache waste with other arrays.
- As you would expect, if your server is IBM, there will be greater integration of storage and server than if your storage is not IBM. That is not because of proprietary protections – IBM makes the server I/O design specs available for others – but instead, it is because of the additional resources that IBM commits in order to have server and storage work together.
If you replicate data to remote sites, the DS8000 offers advantages here as well. Synchronous copies can be made up to 300km distant – three times the usual supported distance. Asynchronous copies are made without using cache or journal files, as with competitive arrays. Since the DS8000 does not rely on cache or journals, it is more autonomic, faster, (3-5 second RPO is common) and more reliable.
Please contact your Mainline Account Executive directly, or click here to contact us with any questions.