Information Architect
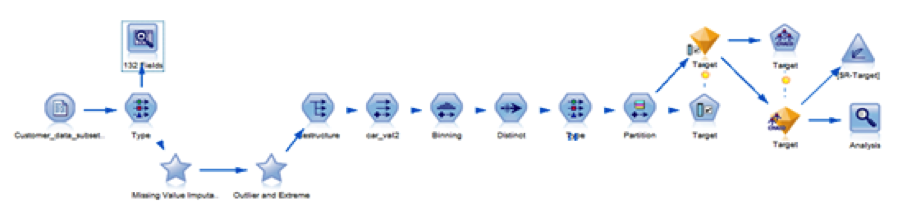
From a dataset of 132 variables (demographic and financial) and over 200 observations, a regular stream for a predictive model shows an average accuracy of 61.55% (correct classifications between training and testing splits).
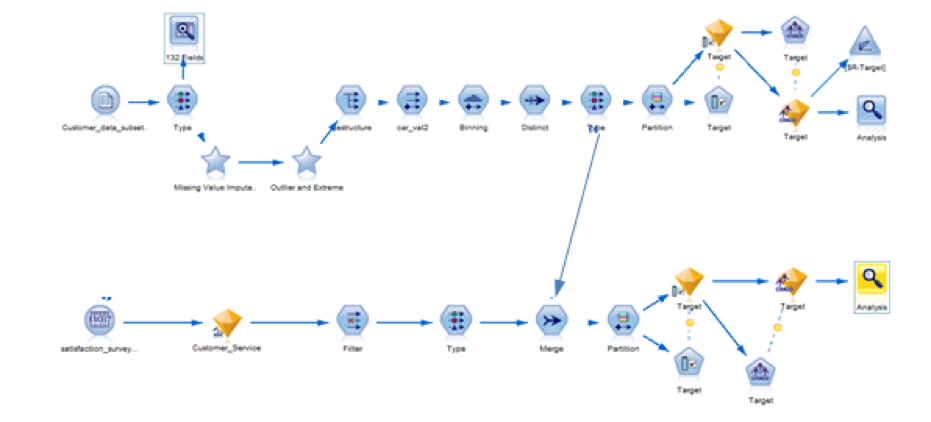
Missing values imputation, outlier treatment, variables binning, partitioning and feature selection were made to predict the variable Target that in this case indicates, whether or not, customers purchased car rental services after a survey was made. CHAID algorithm was used for classification.
Comments and opinions from the survey were processed and used to enhance the previous model predictive power. IBM SPSS Text Analytics engine part of SPSS Modeler 17 Premium was used.
A quick view of the data shows that is unstructured and has no format.
![]()
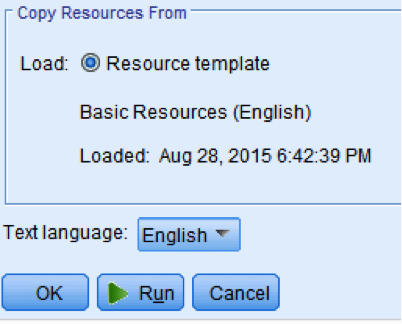
The first step is to load the data and pre-process it selecting the Resource Template from the model tab after adding the text mining icon to the source:

Hit Run. It will take several minutes to pre-process the data.
SPSS automatically classifies terms in pre-existing types and displays results
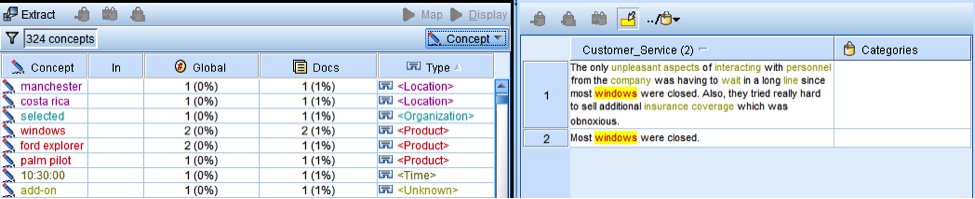
The next step is to assign concepts/term to categories. Categories can be created manually; in this case we are going to let the text mining engine to create categories. Click Categories on the Menu and then select Build Categories
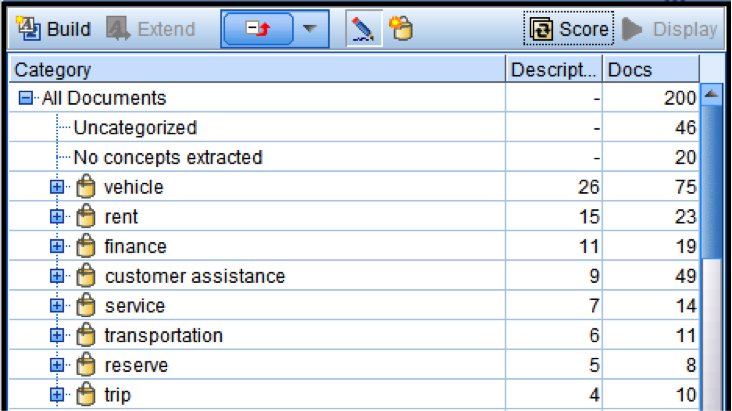
Multiple Categories are created based on contextual data
After categorization is finalized, the Model to structure data can be generated by clicking the golden nugget in the taskbar or the Generate Model option from the Generate Menu.

Click on Golden Nugget to check its properties
The model tab shows previous categories created, descriptor rules, Types and Details. In this case the Customer Service category is related to “work” and “working with” as descriptor “poor woman working” and “person working counter”. This type of associations provide additional context that tokenization does not.
![]()
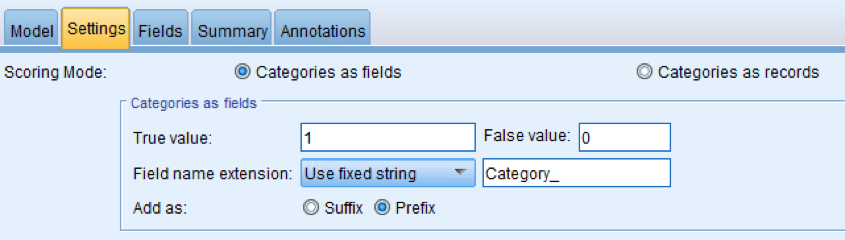
On the settings tab select the Scoring Mode “Categories as Fields”, True value = 1 and False Value =0. This option will create columns for each category created along with 1 or 0 for each record.
If necessary add a filter node.
Add a type node and load/read the new fields/categories created.
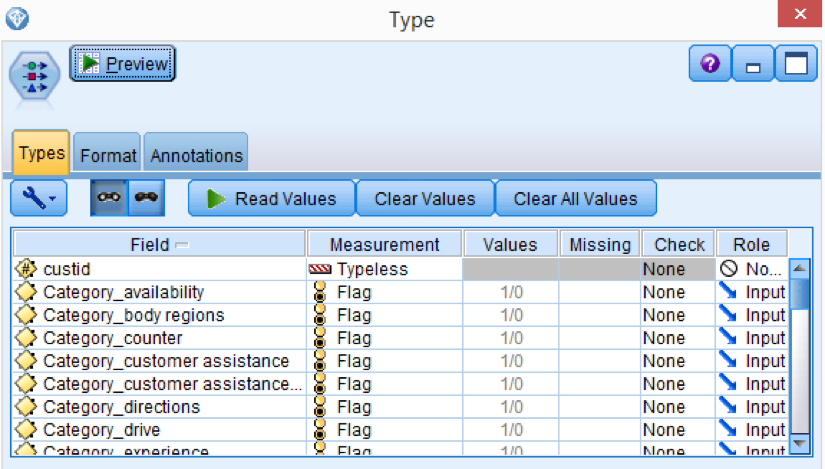
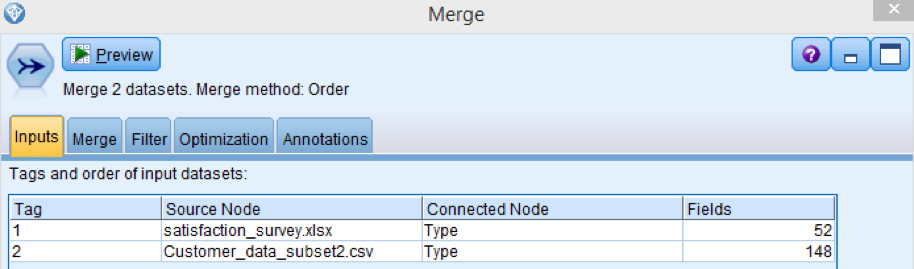
Add a merge node and add connections with the predictive model stream and the text mining stream as well. Click on it to explore the details. On the Inputs tab you will see 2 tags from the 2 sources indicating how many variables has each source.
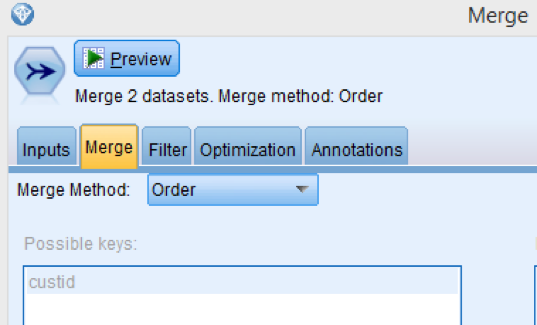
The merge tab shows the field in common (custid) that allows the connection.
Add a partition node to the text mining stream and select the same criteria used in the predictive stream (50% of the obs for training and 50% for testing)
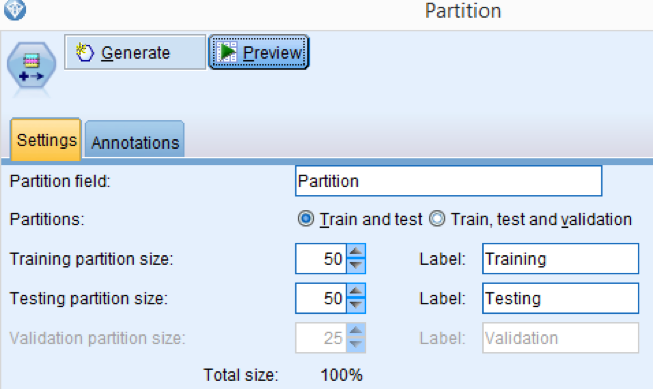
Click OK.
Add a feature selection node and hit RUN (optional).
Add a CHAID Modeling node, make sure the predictor and target fields are populated. Hit RUN.
Finally add an Analysis node and hit RUN.
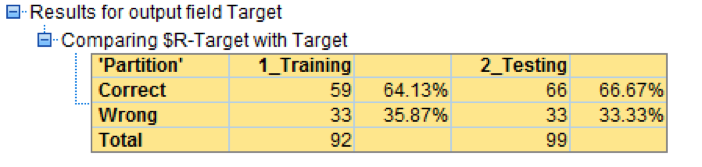
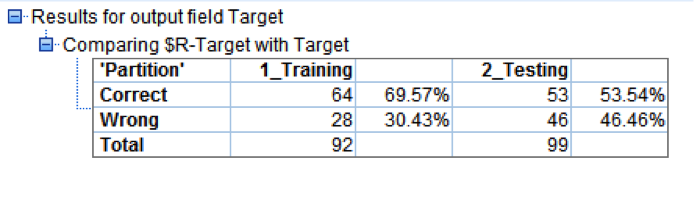
The result is a Model with an average accuracy of 65.4% (almost 4% lift improvement), also more stable because the difference error rate between testing and training is just 2.54% vs 16.03% on the previous model.